
Une nouvelle méthode d’attaque SEO négative a été découverte. Ce qui rend cet exploit particulièrement néfaste, c’est qu’il est pratiquement impossible de détecter l’attaquant. Il n’y a aucun moyen de récupérer si le site Web attaquant est inconnu.
Jusqu’à présent, Google reste silencieux sur la manière dont il compte procéder pour mettre fin à cet exploit dans la manière dont Google classe et déclasse les pages Web.
Il est à noter que cet exploit a été observé mais non testé et vérifié. Si cet exploit est réel, il pourrait potentiellement perturber considérablement les résultats de recherche de Google.
Contents
- 1 Comment l’attaque a été découverte
- 2 Comment fonctionne le référencement négatif canonique
- 3 Que dit la page d’assistance de Google sur Rel=Canonical ?
- 4 Quelle est la réponse de Google ?
- 5 Comment détecter cette attaque
- 6 Google fait-il quelque chose pour arrêter les exploits intersites ?
- 7 Cet exploit est-il réel ?
- 8 Que peut faire Google pour arrêter cet exploit ?
Comment l’attaque a été découverte
L’attaque canonique intersite a été découverte par Bill Hartzer de Hartzer Consulting. Une entreprise l’a approché au sujet d’une baisse soudaine de son classement. Au cours de l’examen des backlinks, Hartzer a découvert des liens vers un site étrange.
Mais le client n’a pas établi de lien vers ce site. L’enquête sur cet autre site l’a conduit au site de référencement négatif.
Si ce site attaquant n’avait pas établi de lien vers la troisième page, Hartzer n’aurait pas été en mesure d’identifier le site Web attaquant. C’est grâce au nouvel index de la société d’exploration de données SEO Majestic qui comprend des données canoniques que Hartzer a pu découvrir le site attaquant. (Note de l’éditeur : Hartzer est un ambassadeur de la marque Majestic.)

Comment fonctionne le référencement négatif canonique
L’attaque fonctionne en copiant l’intégralité de la section « en-tête » de la page Web de la victime dans la section d’en-tête de la page Web de spam, y compris la balise canonique. La balise canonique indique à Google que cette page de spam est la page Web de la victime.
Google attribue alors vraisemblablement tout le contenu (et les scores de spam négatifs) de la page Web de spam à la page Web de la victime.
Que dit la page d’assistance de Google sur Rel=Canonical ?
Voici la propre page d’assistance de Google sur la façon dont Google gère rel=canonical. Ce qui suit provient de la page d’assistance de Google :
Pourquoi devrais-je choisir une URL canonique ?
Il existe un certain nombre de raisons pour lesquelles vous voudriez choisir explicitement une page canonique dans un ensemble de pages en double/similaires :
-
Pour consolider les signaux de lien pour des pages similaires ou en double. Cela aide les moteurs de recherche à consolider les informations dont ils disposent pour les URL individuelles (telles que les liens vers celles-ci) en une seule URL préférée. Cela signifie que les liens provenant d’autres sites vers
http://example.com/dresses/cocktail?gclid=ABCDêtre consolidé avec des liens vershttps://www.example.com/dresses/green/greendress.html.
Quelle est la réponse de Google ?
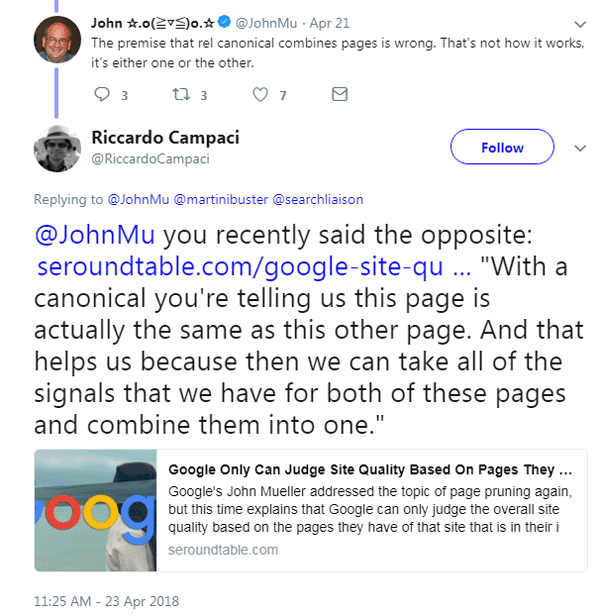
Jusqu’à présent, Google semble s’être concentré sur le rejet de l’idée sans enquêter. John Mueller a tweeté que Rel-Canonical était une technologie vieille de dix ans et que quelque chose comme celui-ci aurait déjà fait surface. Voici ce que « Mueller de Google a tweeté :
Le rel canonique existe depuis plus d’une décennie, les gens ont essayé beaucoup de choses avec. C’est un signal de canonisation ; une URL gagne, les explorations des autres sont abandonnées.
Son argument est contredit par le récent XML Sitemap Exploit, officiellement confirmé par Google. Ce n’est pas parce qu’une technologie a dix ans qu’elle ne peut pas être exploitée.. Le récent XML Sitemap Exploit contredit la déclaration de Mueller.
De plus, Rel=Canonical fait plus qu’affecter le budget d’exploration. Comme vous pouvez le voir sur la page d’assistance Google citée ci-dessus, Rel=Canonical combine les scores de liens.
Mueller a poursuivi et a déclaré :
« L’hypothèse selon laquelle rel canonique combine des pages est fausse. Ce n’est pas comme ça que ça marche, c’est soit l’un, soit l’autre. »
Mais quelqu’un d’autre sur Twitter a souligné que cette déclaration contredit les propres mots de Mueller où il a déclaré dans une interview:
« Avec un canonique, vous nous dites que cette page est en fait la même que cette autre page. Et cela nous aide car nous pouvons alors prendre tous les signaux que nous avons pour ces deux pages et les combiner en un seul. «
Le résultat est que la victime perd sa capacité à se classer, probablement à cause de tous les signaux de spam négatifs attribués au site de la victime.
- La déclaration n°1 de Google, selon laquelle Rel-Canonicals a dix ans, n’est pas une raison valable pour rejeter l’alerte de Hartzer. L’exploit XML Sitemap confirmé contredit la déclaration de Google.
- La déclaration n°2 de Google, selon laquelle les rel-canoniques ne combinent pas de pages, n’est pas valide, car les propres mots de Mueller et la propre page d’assistance de Google contredisent son affirmation.
Les éditeurs se sentiront peut-être un peu mieux de savoir que Google prend le rapport au sérieux et l’examine. C’est une meilleure réponse que de ne pas examiner le rapport et de simplement le rejeter avec des déclarations contradictoires.
Comment détecter cette attaque
J’ai demandé à Hartzer s’il existait un autre moyen de détecter ces attaques. Il a déclaré avoir essayé un certain nombre d’outils logiciels, notamment Copyscape et bien d’autres. Mais jusqu’à présent, seul Majestic a pu identifier certains des sites attaquants.
« J’ai essayé le moteur de recherche de code source publicwww mais il n’affiche pas les données – seul Majestic montre réellement la relation, et c’est parce que celui qui effectue le référencement négatif a établi un lien », a déclaré Hartzer. « Dans les autres cas que j’ai découverts, cependant, le site n’établit pas de lien. Je sais qu’il y a d’autres sites sur lesquels ils font cela… j’en ai vu quelques autres. »
Google fait-il quelque chose pour arrêter les exploits intersites ?
Kristine Schachinger, qui a récemment identifié un exploit similaire, a fait les observations suivantes :
« Habituellement, la méthode d’attaque et les résultats peuvent être directement reliés les uns aux autres. Mais cette fois, le vecteur de l’attaque n’est pas le site attaqué, mais une faiblesse des algorithmes de Google. «
L’attaque est basée sur le fait que Google « perçoit » les deux sites comme un seul. Cela transfère des variables positives ou négatives entre les sites de l’attaquant et de la victime.
La confusion persiste pendant un certain temps, ce qui signifie que l’attaque est permanente au-delà du cycle de vie de l’attaque réelle. Il s’agit d’un problème Google qui ne semble pas être activement résolu par Google.
Cet exploit est-il réel ?
Cet exploit a été documenté comme étant arrivé à plusieurs sites. Mais il convient de noter qu’aucune expérience n’a été menée jusqu’à présent pour confirmer que ce type d’attaque est possible.
Que peut faire Google pour arrêter cet exploit ?
Si cet exploit est réel, il a des implications sur la manière dont Google et Bing utilisent la balise canonique.
En pratique, la balise canonique n’est pas une directive. Cela signifie que contrairement à un fichier Robots.txt, les moteurs de recherche ne sont pas obligés d’obéir à la balise canonique. La balise canonique est traitée par les moteurs de recherche comme une suggestion.
S’il s’agit d’une faille dans le fonctionnement de la balise canonique, une solution possible pourrait consister pour les moteurs de recherche à mettre à jour les spécifications canoniques afin qu’elles ne puissent plus être utilisées pour canoniser dans différents domaines. Idéalement, cela devrait être fait via la Google Search Console.
Plus de ressources
Images de Shutterstock, modifiées par l’auteur